A practical approach to non blocking file IO
Speed of execution and Optimal use of computing resources are the main goals of computer algorithms, frameworks and programs. The speed of access to data is one of the main factors that determine the efficiency of applications, in terms of response time as well as scalability.
Time to access memory varies based on the type of memory, it increases in the order of L1, L2, L3 cache, Primary memory, Secondary memory (disk access inclusive of SSD disks). Disk access is is several orders of magnitude slower than memory access milliseconds for HDD and microseconds for SSD vs nanoseconds for memory (in modern CPU).
Buffering is implemented by standard libraries (libc) as well as OS (buffered IO), in order to improve the data access speed by programs. The main assumption in this scheme is the principle of Temporal locality of reference (data accessed once will, with a high likelihood, find itself accessed again in the near future).
It is important to note that the principle of temporal locality of reference, does not become beneficial in all circumstances. Server-side programs for example, process incoming data file via HTTP, FTP, or they generate output to files in case of, reports, logs, files to be sent to other systems. In all these cases, data once read and processed or data once written to disk will not be referred again. It will be a waste of memory to hold the pages from these files in the cache.
One more consideration in this is the issue of scalability and threading model. The strategy of DMA allows a thread needing to carryout IO to be blocked and another thread be scheduled for processing by CPU until the IO requested by the original thread is complete. In case of multi-threaded server programs, when one threads blocks for some IO (file/socket) other threads process newer requests. The blocked ones continue their processing once the IO is complete. In such a scenario, it becomes complex to estimate the number of threads that need to be started.
Solution to the above problem is attempted by frameworks that implement asynchronous IO such as AIO, IOCP. They offload the task of IO to a pool of background threads thus freeing up the worker threads (which submit the IO requests) to process other tasks (such as newer requests), while IO is being completed. Once the IO is completed, the suspended task is continued further.
One limitation in these frameworks is that both read and write file operations are offloaded to background threads. There is a significant difference between the read and write operations.
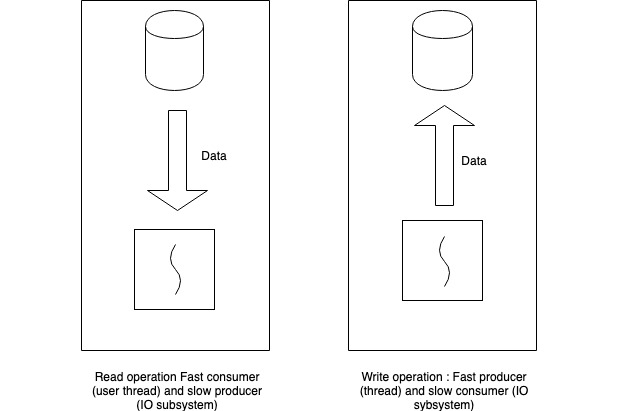
In case of read operation: the source of data is the disk and the consumer is the worker thread. It is a case of very slow producer and a fast consumer. Once the request is submitted to the producer of data, the consumer (the thread) can do other tasks while the data is being fetched.
In case of write operation: the source of data (producer) is fast and the destination (consumer or the disk) is slow. Thus the activity of context switching to achieve asynchronous IO will be costlier as against buffering the data in memory and have a background thread to sync the buffered data to disk in a slow syncing mechanism. This strategy will produce better results for the worker threads as far as response times are concerned.
There is a necessity of a file handling library, which solves both the problems mentioned above,
- Avoiding OS buffer for files not accessed again and
- Implement the desirable async IO strategy for read and write.
Tekenlight is attempting this approach through a file IO library called efio, this is still going through various stages of development, review and test. The library is planned to be available through liberal open source licensing policy.
PS
Feedback/Comments/suggestions, as well as contributions on this are welcome.
© Tekenlight Solutions Pvt Ltd 2019. All Rights Reserved.
Contact us: sudheer.hr@tekenlight.com
github.com/Tekenlight
Disclaimer: This blog is built using Jekyll and is heavily inspired by Tom Preston-Werner's personal blog

